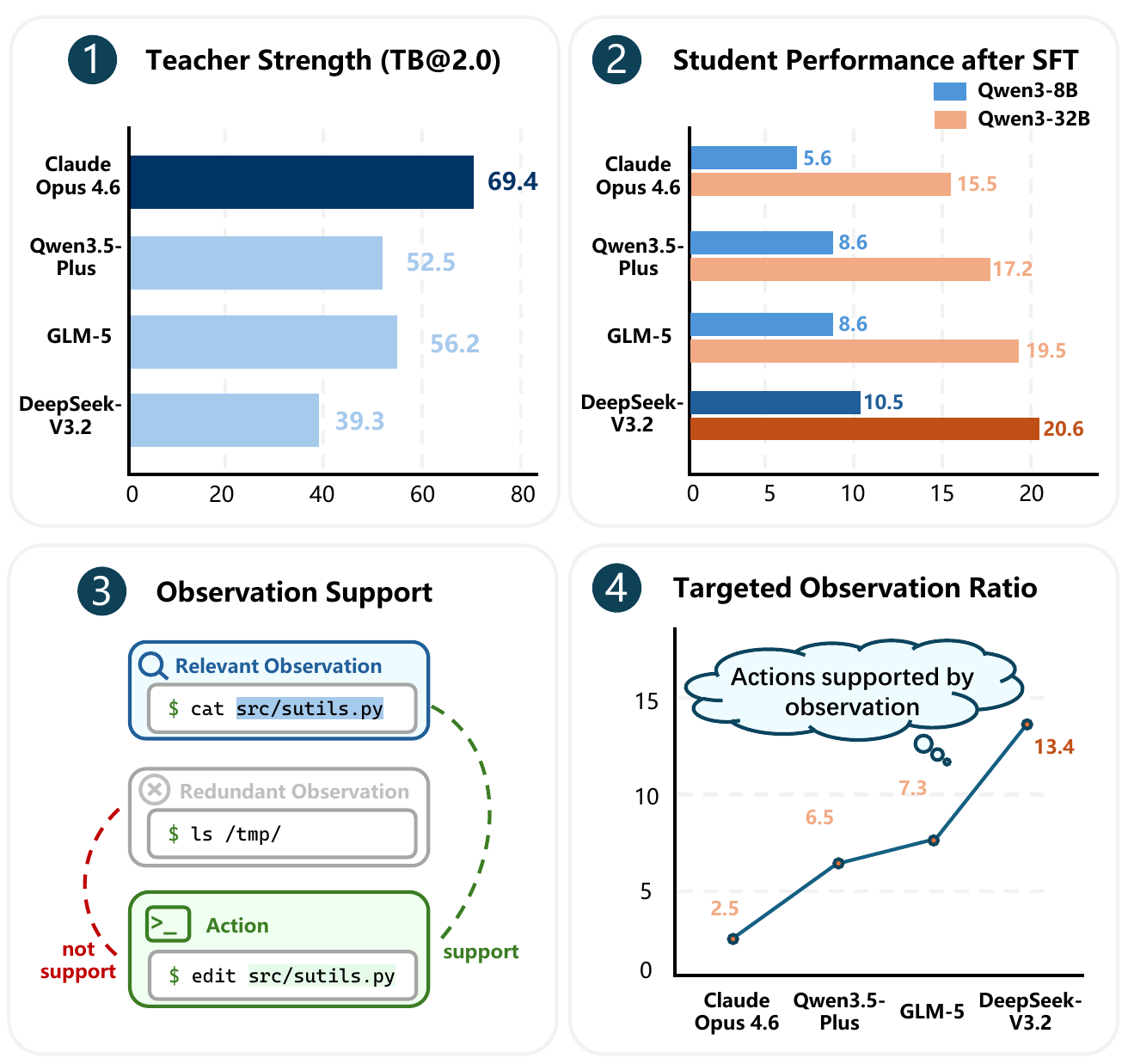
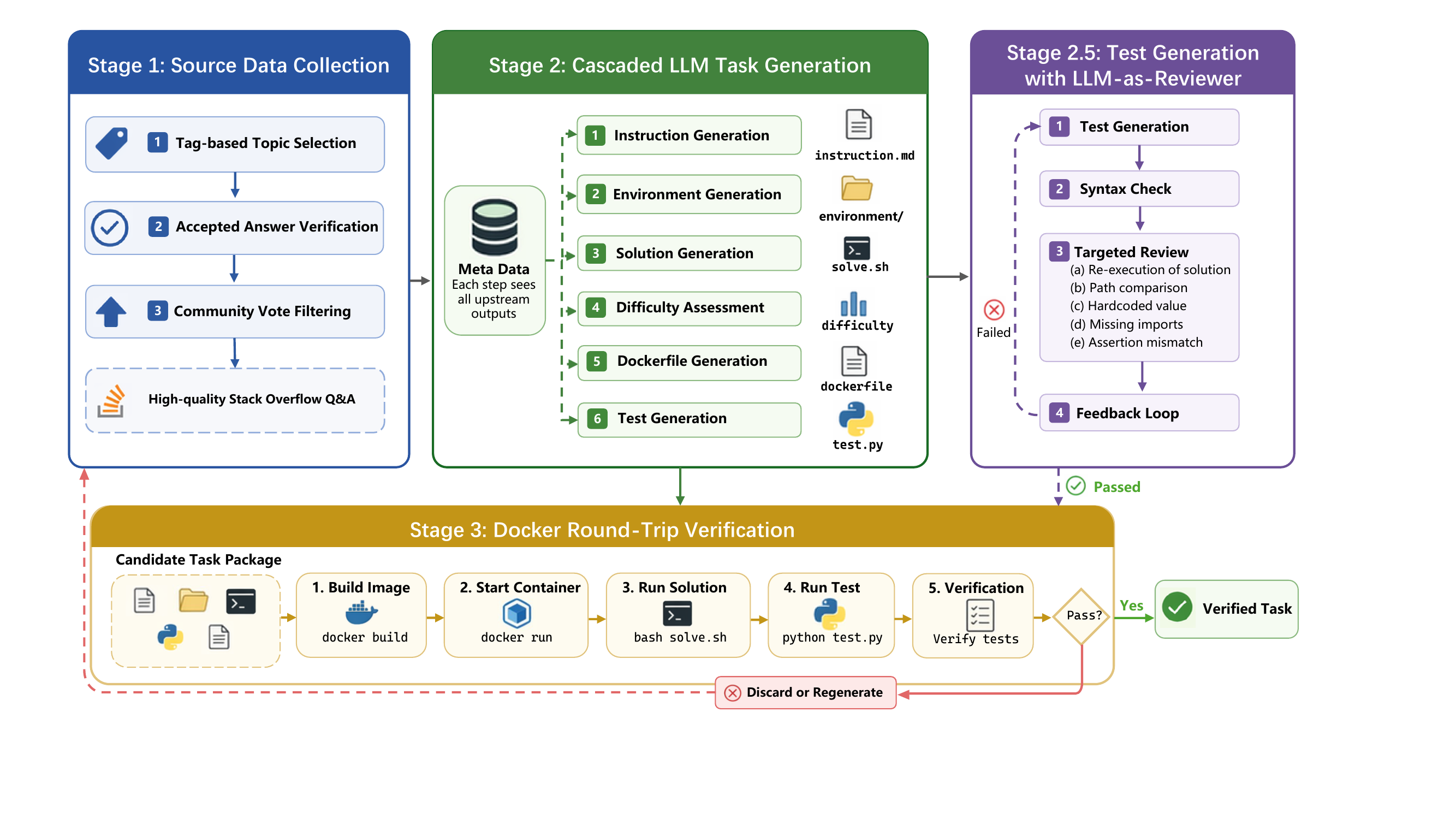
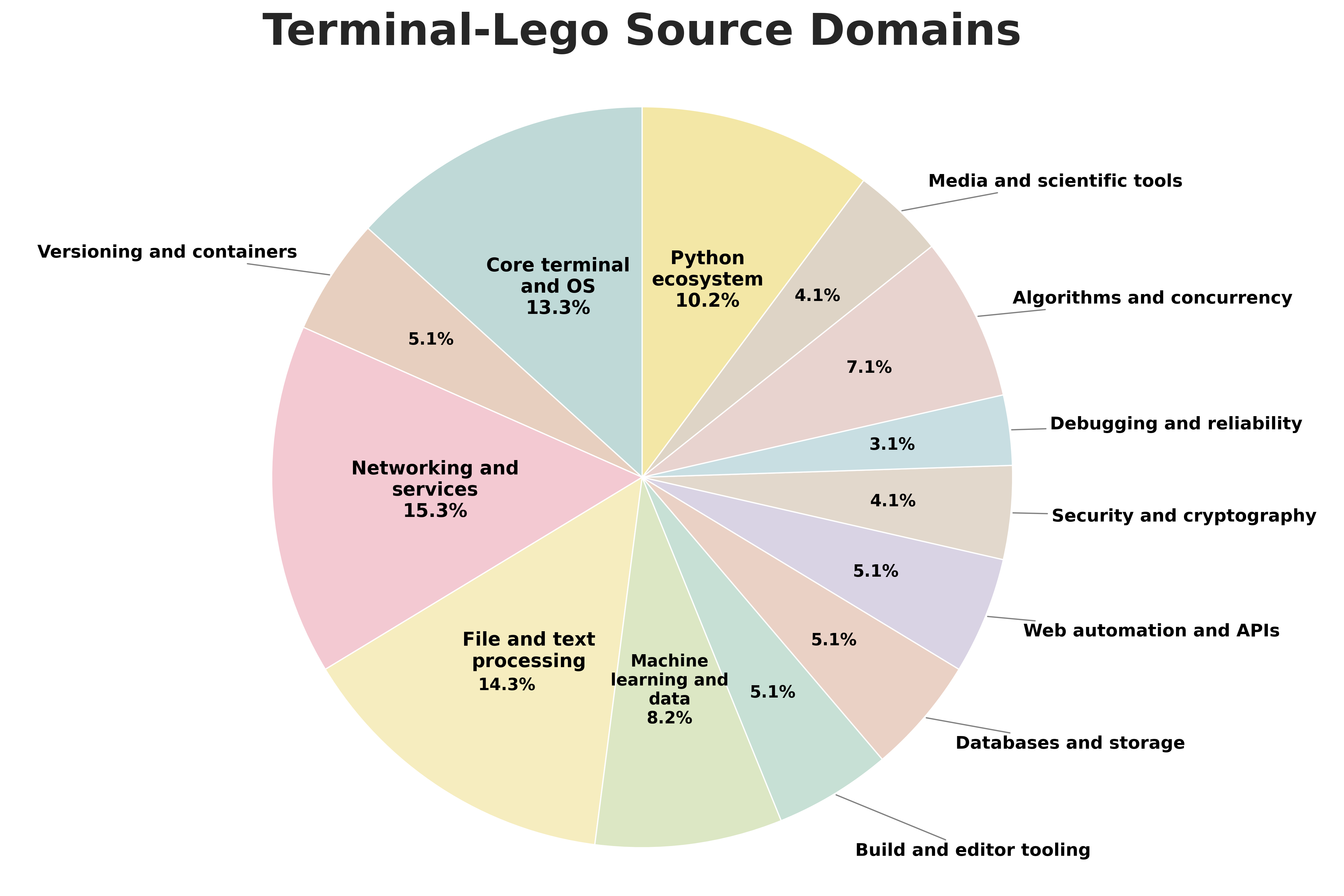
Prioritize Paradigm over Performance — When selecting teacher models for distillation, prioritize those with rigorous inspect-act-verify habits (high TOR) rather than those with the highest benchmark scores.
Observation as the Core Reasoning Primitive — Environment-grounded observation is not merely a safety check, but the fundamental bridge between perception and action that students must learn.
The Value of Methodological Failure — Sufficiently capable students can extract reusable interaction patterns from imperfect trajectories, decoupling process quality from outcome.